iOS原理分析之从源码看load与initialize方法
一、引言
在iOS开发中,NSObject类是万事万物的基类,其在Objective-C的整理类架构中非常重要,其中有两个很有名的方法:load方法与initialize方法。
1
2
| + (void)load;
+ (void)initialize;
|
说起这两个方法,你的第一反应一定是觉得太老套了,这两个方法的调用时机及作用几乎成为了iOS面试的必考题。其本身调用时机也非常简单:
1. load方法在pre-main阶段被调用,每个类都会调用且只会调用一次。
2. initialize方法在类或子类第一次进行方法调用前会调用。
上面的两点说明本身是正确的,但是除此之外,还有许多问题值得我们深究,例如:
1. 子类与父类的load方法的调用顺序是怎样的?
2. 类与分类的load方法调用顺序是怎样的?
3. 子类未实现load方法,会调用父类的么?
4. 当有多个分类都实现了load方法时,会怎么样?
5. 每个类的load方法的调用顺序是怎样的?
6. 父类与子类的initialize的方法调用顺序是怎样的?
7. 子类实现initialize方法后,还会调用父类的initialize方法么?
8. 多个分类都实现了initialize方法后,会怎么样?
9. …
如上所提到的问题,你现在都能给出明确的答案么?其实,load与initialize方法本身还有许多非常有意思的特点,本篇博客,我们将结合Objective-C源码,对这两个方法的实现原理做深入的分析,相信,如果你对load与initialize还不够了解,不能完全明白上面所提出的问题,那么本篇博客将会使其收获满满。无论在以后的面试中,还是工作中使用到load和initialize方法时,都可能帮助你从源码上理解其执行原理。
二、实践出真知 - 先看load方法
在开始分析之前,我们首先可以先创建一个测试工程,对load方法的执行时机先做一个简单的测试。首先,我们创建一个Xcode的命令行程序工程,在其中创建一些类、子类和分类,方便我们测试,目录结构如下图所示:
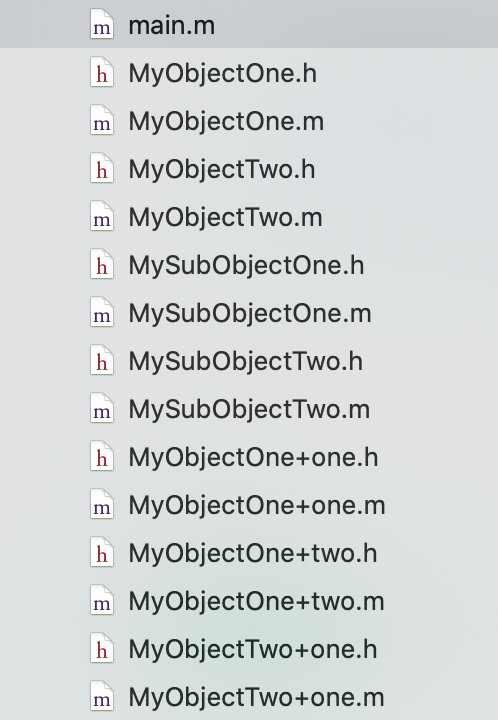
其中,MyObjectOne和MyObjectTwo都是继承自NSObject的类,MySubObjectOne是MyObjectOne的子类,MySubObjectTwo是MyObjectTwo的子类,同时我们还创建了3个分类,在类中实现load方法,并做打印处理,如下:
1
2
3
| + (void)load {
NSLog(@"load:%@", [self className]);
}
|
同样,类似的也在分类中做实现:
1
2
3
| + (void)load {
NSLog(@"load-category:%@", [self className]);
}
|
最后我们在main函数中添加一个Log:
1
2
3
4
5
6
| int main(int argc, const char * argv[]) {
@autoreleasepool {
NSLog(@"Main");
}
return 0;
}
|
运行工程,打印结果如下:
1
2
3
4
5
6
7
8
| 2021-02-18 14:33:46.773294+0800 KCObjc[21400:23090040] load:MyObjectOne
2021-02-18 14:33:46.773867+0800 KCObjc[21400:23090040] load:MySubObjectOne
2021-02-18 14:33:46.773959+0800 KCObjc[21400:23090040] load:MyObjectTwo
2021-02-18 14:33:46.774008+0800 KCObjc[21400:23090040] load:MySubObjectTwo
2021-02-18 14:33:46.774052+0800 KCObjc[21400:23090040] load-category:MyObjectTwo
2021-02-18 14:33:46.774090+0800 KCObjc[21400:23090040] load-category:MyObjectOne
2021-02-18 14:33:46.774127+0800 KCObjc[21400:23090040] load-category:MyObjectOne
2021-02-18 14:33:46.774231+0800 KCObjc[21400:23090040] Main
|
从打印结果可以看出,load方法在main方法开始之前被调用,执行顺序上来说,先调用类的load方法,再调用分类的load方法,从父子类的关系上看来,先调用父类的load方法,再调用子类的load方法。
下面,我们就从源码上来分析下,系统如此调用load方法,是源自于什么样的奥妙。
三、从源码分析load方法的调用
要深入的研究load方法,我们首先需要从Objective-C的初始化函数说起:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| void _objc_init(void)
{
static bool initialized = false;
if (initialized) return;
initialized = true;
environ_init();
tls_init();
static_init();
runtime_init();
exception_init();
cache_init();
_imp_implementationWithBlock_init();
_dyld_objc_notify_register(&map_images, load_images, unmap_image);
#if __OBJC2__
didCallDyldNotifyRegister = true;
#endif
}
|
_objc_init函数定义在objc-os.mm文件中,这个函数用来做Objective-C程序的初始化,由引导程序进行调用,其调用实际会非常的早,并且是操作系统引导程序复杂调用驱动,对开发者无感。在_objc_init函数中,会进行环境的初始化,runtime的初始化以及缓存的初始化等等操作,其中很重要的一步操作是执行_dyld_objc_notify_register函数,这个函数会调用load_images函数来进行镜像的加载。
load方法的调用,其实就是类加载过程中的一步,首先,我们先来看一个load_images函数的实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| void
load_images(const char *path __unused, const struct mach_header *mh)
{
if (!didInitialAttachCategories && didCallDyldNotifyRegister) {
didInitialAttachCategories = true;
loadAllCategories();
}
if (!hasLoadMethods((const headerType *)mh)) return;
recursive_mutex_locker_t lock(loadMethodLock);
{
mutex_locker_t lock2(runtimeLock);
prepare_load_methods((const headerType *)mh);
}
call_load_methods();
}
|
滤掉其中我们不关心的部分,与load方法调用相关的核心如下:
1
2
3
4
5
6
7
8
9
10
11
12
| void
load_images(const char *path __unused, const struct mach_header *mh)
{
if (!hasLoadMethods((const headerType *)mh)) return;
{
prepare_load_methods((const headerType *)mh);
}
call_load_methods();
}
|
最核心的部分在于load方法的准备与laod方法的调用,我们一步一步看,先来看load方法的准备(我们去掉了无关紧要的部分):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| void prepare_load_methods(const headerType *mhdr)
{
size_t count, i;
classref_t const *classlist =
_getObjc2NonlazyClassList(mhdr, &count);
for (i = 0; i < count; i++) {
schedule_class_load(remapClass(classlist[i]));
}
category_t * const *categorylist = _getObjc2NonlazyCategoryList(mhdr, &count);
for (i = 0; i < count; i++) {
category_t *cat = categorylist[i];
add_category_to_loadable_list(cat);
}
}
|
看到这里,我们基本就有头绪了,load方法的调用顺序,基本可以确定是由整理过程所决定的,并且我们可以发现,类的load方法整理与分类的load方法整理是互相独立的,因此也可以推断其调用的时机也是独立的。首先我们先来看类的load方法整理函数schedule_class_load(去掉无关代码后):
1
2
3
4
5
6
7
8
9
10
11
12
13
| static void schedule_class_load(Class cls)
{
if (!cls) return;
if (cls->data()->flags & RW_LOADED) return;
schedule_class_load(cls->superclass);
add_class_to_loadable_list(cls);
cls->setInfo(RW_LOADED);
}
|
可以看到,schedule_class_load函数中使用了递归的方式演着继承链逐层向上,保证在加载load方法时,先加载父类,再加载子类。add_class_to_loadable_list是核心的load方法整理函数,如下(去掉了无关代码):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| void add_class_to_loadable_list(Class cls)
{
IMP method;
method = cls->getLoadMethod();
if (!method) return;
if (loadable_classes_used == loadable_classes_allocated) {
loadable_classes_allocated = loadable_classes_allocated*2 + 16;
loadable_classes = (struct loadable_class *)
realloc(loadable_classes,
loadable_classes_allocated *
sizeof(struct loadable_class));
}
loadable_classes[loadable_classes_used].cls = cls;
loadable_classes[loadable_classes_used].method = method;
loadable_classes_used++;
}
|
loadable_clas结构体的定义如下:
1
2
3
4
| struct loadable_class {
Class cls;
IMP method;
};
|
getLoadMetho函数的实现主要是从类中获取到load方法的实现,如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| IMP
objc_class::getLoadMethod()
{
const method_list_t *mlist;
mlist = ISA()->data()->ro()->baseMethods();
if (mlist) {
for (const auto& meth : *mlist) {
const char *name = sel_cname(meth.name);
if (0 == strcmp(name, "load")) {
return meth.imp;
}
}
}
return nil;
}
|
现在,关于类的load方法的准备逻辑已经非常清晰了,最终会按照先父类后子类的顺序将所有类的load方法添加进名为loadable_classes的列表中,loadable_classes这个名字你要注意一下,后面我们还会遇到它。
我们再来看分类的laod方法准备过程,其与我们上面介绍的类非常相似,add\_category\_to\_loadable\_list函数简化后如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void add_category_to_loadable_list(Category cat)
{
IMP method;
method = _category_getLoadMethod(cat);
if (!method) return;
if (loadable_categories_used == loadable_categories_allocated) {
loadable_categories_allocated = loadable_categories_allocated*2 + 16;
loadable_categories = (struct loadable_category *)
realloc(loadable_categories,
loadable_categories_allocated *
sizeof(struct loadable_category));
}
loadable_categories[loadable_categories_used].cat = cat;
loadable_categories[loadable_categories_used].method = method;
loadable_categories_used++;
}
|
可以看到,最终分类的load方法是存储在了loadable_categories列表中。
准备好了load方法,我们再来分析下load方法的执行过程,call\_load\_methods函数的核心实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| void call_load_methods(void)
{
bool more_categories;
do {
while (loadable_classes_used > 0) {
call_class_loads();
}
more_categories = call_category_loads();
} while (loadable_classes_used > 0 || more_categories);
}
|
call_class_loads函数实现简化后如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| static void call_class_loads(void)
{
int i;
struct loadable_class *classes = loadable_classes;
int used = loadable_classes_used;
loadable_classes = nil;
loadable_classes_allocated = 0;
loadable_classes_used = 0;
for (i = 0; i < used; i++) {
Class cls = classes[i].cls;
load_method_t load_method = (load_method_t)classes[i].method;
if (!cls) continue;
(*load_method)(cls, @selector(load));
}
}
|
call_category_loads函数的实现要复杂一些,简化后如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| static bool call_category_loads(void)
{
int i, shift;
bool new_categories_added = NO;
struct loadable_category *cats = loadable_categories;
int used = loadable_categories_used;
int allocated = loadable_categories_allocated;
loadable_categories = nil;
loadable_categories_allocated = 0;
loadable_categories_used = 0;
for (i = 0; i < used; i++) {
Category cat = cats[i].cat;
load_method_t load_method = (load_method_t)cats[i].method;
Class cls;
if (!cat) continue;
cls = _category_getClass(cat);
if (cls && cls->isLoadable()) {
(*load_method)(cls, @selector(load));
cats[i].cat = nil;
}
}
return new_categories_added;
}
|
现在,我相信你已经对load方法为何类先调用,分类后调用,并且为何父类先调用,子类后调用。但是还有一点,我们不甚明了,即类之间或分类之间的调用顺序是怎么确定的,从源码中可以看到,类列表是通过_getObjc2NonlazyClassList函数获取的,同样分类的列表是通过_getObjc2NonlazyCategoryList函数获取的。这两个函数获取到的类或分类的顺序实际上是与类源文件的编译顺序有关的,如下图所示:
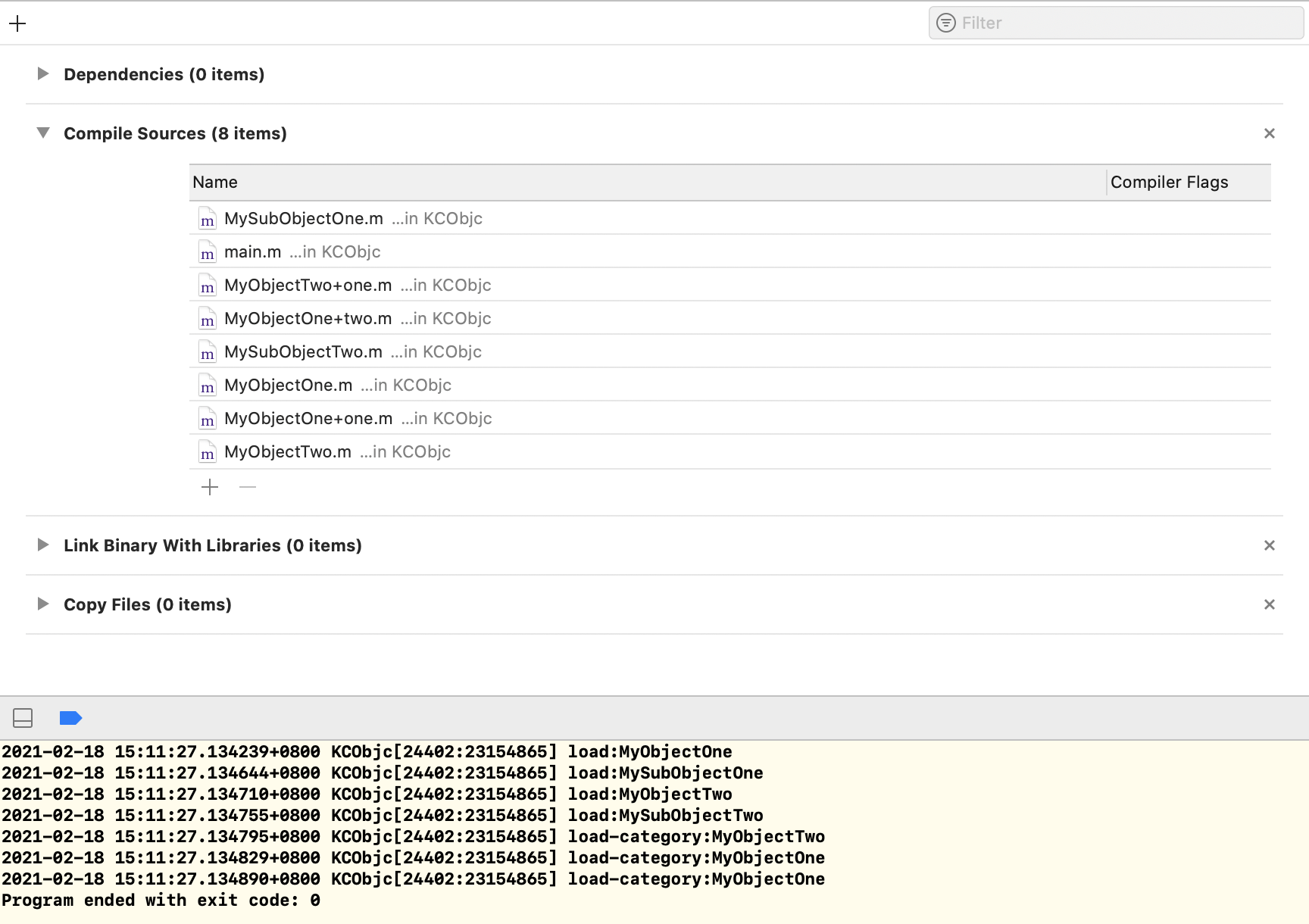
可以看到,打印的load方法的执行顺序与源代码的编译顺序是一直的。
四、initialize方法分析
我们可以采用和分析load方法时一样的策略来对initialize方法的执行情况,进行测试,首先将测试工程中所有类中添加initialize方法的实现。此时如果直接运行工程,你会发现控制台没有任何输出,这是由于只有第一次调用类的方法时,才会执行initialize方法,在main函数中编写如下测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
| int main(int argc, const char * argv[]) {
@autoreleasepool {
[MySubObjectOne new];
[MyObjectOne new];
[MyObjectTwo new];
NSLog(@"------------");
[MySubObjectOne new];
[MyObjectOne new];
[MyObjectTwo new];
}
return 0;
}
|
运行代码控制台打印效果如下:
1
2
3
4
| 2021-02-18 21:29:55.761897+0800 KCObjc[43834:23521232] initialize-cateOne:MyObjectOne
2021-02-18 21:29:55.762526+0800 KCObjc[43834:23521232] initialize:MySubObjectOne
2021-02-18 21:29:55.762622+0800 KCObjc[43834:23521232] initialize-cate:MyObjectTwo
2021-02-18 21:29:55.762665+0800 KCObjc[43834:23521232] ------------
|
可以看到,打印数据都出现在分割线前,说明一旦一个类的initialize方法被调用后,后续再向这个类发送消息,也不会在调用initialize方法,还有一点需要注意,需要注意,如果对子类发送消息,父类的initialize会先调用,再调用子类的initialize,同时,分类中如果实现了initialize方法则会覆盖类本身的,并且分类的加载顺序靠后的会覆盖之前的。下面我们就通过源码来分析下initialize方法的这种调用特点。
首先,在调用类的类方法时,会执行runtime中的class_getClassMethod方法来寻找实现函数,这个方法在源码中的实现如下:
1
2
3
4
5
| Method class_getClassMethod(Class cls, SEL sel)
{
if (!cls || !sel) return nil;
return class_getInstanceMethod(cls->getMeta(), sel);
}
|
通过源码可以看到,调用一个类的类方法,实际上是调用其元类的示例方法,getMeta函数用来获取类的元类,关于类和元类的相关组织原理,我们这里先不扩展。我们需要关注的是class_getInstanceMethod这个函数,这个函数的实现也非常简单,如下:
1
2
3
4
5
6
7
8
9
10
| Method class_getInstanceMethod(Class cls, SEL sel)
{
if (!cls || !sel) return nil;
lookUpImpOrForward(nil, sel, cls, LOOKUP_RESOLVER);
return _class_getMethod(cls, sel);
}
|
在class_getInstanceMethod方法的实现中,_class_getMethod是最终获取要调用的方法的函数,在这之前,lookUpImpOrForward函数会做一些前置操作,其中就有initialize函数的调用逻辑,我们去掉无关的逻辑,lookUpImpOrForward中核心的实现如下:
1
2
3
4
5
6
7
8
9
10
| IMP lookUpImpOrForward(id inst, SEL sel, Class cls, int behavior)
{
IMP imp = nil;
if (slowpath((behavior & LOOKUP_INITIALIZE) && !cls->isInitialized())) {
cls = initializeAndLeaveLocked(cls, inst, runtimeLock);
}
return imp;
}
|
initializeAndLeaveLocked会直接调用initializeAndMaybeRelock函数,如下:
1
2
3
4
| static Class initializeAndLeaveLocked(Class cls, id obj, mutex_t& lock)
{
return initializeAndMaybeRelock(cls, obj, lock, true);
}
|
initializeAndMaybeRelock函数中会做类的初始化逻辑,这个过程是线程安全的,其核心相关代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| static Class initializeAndMaybeRelock(Class cls, id inst,
mutex_t& lock, bool leaveLocked)
{
if (cls->isInitialized()) {
return cls;
}
Class nonmeta = getMaybeUnrealizedNonMetaClass(cls, inst);
initializeNonMetaClass(nonmeta);
return cls;
}
|
initializeNonMetaClass函数会采用递归的方式沿着继承链向上查询,找到所有未初始化过的父类进行初始化,核心实现简化如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| void initializeNonMetaClass(Class cls)
{
Class supercls;
bool reallyInitialize = NO;
supercls = cls->superclass;
if (supercls && !supercls->isInitialized()) {
initializeNonMetaClass(supercls);
}
SmallVector<_objc_willInitializeClassCallback, 1> localWillInitializeFuncs;
{
if (!cls->isInitialized() && !cls->isInitializing()) {
cls->setInitializing();
reallyInitialize = YES;
}
}
if (reallyInitialize) {
@try
{
callInitialize(cls);
}
@catch (...) {
@throw;
}
return;
}
}
|
callInitialize函数最终会调用objc_msgSend函数来向类发送initialize初始化消息,如下:
1
2
3
4
5
| void callInitialize(Class cls)
{
((void(*)(Class, SEL))objc_msgSend)(cls, @selector(initialize));
asm("");
}
|
需要注意,initialize方法与load方法最大的区别在于其最终是通过objc_msgSend来实现的,每个类如果未初始化过,都会通过objc_msgSend来向类发送一次initialize消息,因此,如果子类没有对initialize实现,按照objc_msgSend的消息机制,其是会沿着继承链一路向上找到父类的实现进行调用的,所有initialize方法并不是只会被调用一次,假如父类中实现了这个方法,并且它有多个未实现此方法的子类,则当每个子类第一次接受消息时,都会调用一遍父类的initialize方法,这点非常重要,在实际开发中一定要牢记。
五、结语
load和initialize方法是iOS开发中非常简单也也非常常用的两个方法,然而其与普通的方法比起来,还有有一些特殊,通过对源码的解读,我们可以更加深刻的理解这些特殊之处的原因及原理,编程的过程就像修行,知其然也知其所以然,与大家共勉。
专注技术,热爱生活,交流技术,也做朋友。
——珲少 QQ群:805263726